深入思考如何做好公司的稳定性保障工作?这句话说的,其实一语双关,既要保障公司整体业务环境高可用,又是对自己下半年稳定工作的一大契机。可以说这个过程充满了机遇,同时也是挑战。需要运用自己多年积累的职场经验,这里面不仅仅是指我丰富的运维专业的工作经历,同时也是要注重日常总结沉淀,更好地提升团队工作效率。
如图介绍的是一幅构建SRE 架构思维导图。
在云时代,客户体验是所有重要企业的新口号,即使命宣言。客户体验、可用性和可访问性是在端决定的,在这里站点应当始终可用。对用户来说,可靠性才是最重要的;一个未使用的应用程序对用户和企业毫无价值。
如今,每家公司都在努力推动科技变革。公司业务战略都围绕云功能构建。这对他们来说是一项重大的运维挑战。站点性能下降、客户体验的下降都将导致现金、收入和竞争力的损失,并导致传统运维无法应对可观测性的大问题(包括实时监控和告警)。
为什么存在SRE?敏捷运动提升了跨职能团队之间协作的重要性,这催生了DevOps .
DevOps 是关于深入研究自己组织的具体问题和挑战的。它还与速度、效率和质量有关。从本质上将,它是一种以实现组织的预期结果的文化、一种运动、一种价值观、原则、方法和实践。
这种速度也造成了一定的不稳定性,开发人员的行动速度比以往任何时候都快了,但却给运维团队带来了挑战。IT运维团队没有能力应对这样的速度,这让他们遇到了瓶颈和严重的积压,导致生产中产生了不稳定的因素,结果使系统变得不可靠。因此,Google提出了对SRE的要求: “一群能够将工程专业知识应用于运维问题的开发人员。”
SRE 是一种规范的DevOps方式。它是系统管理任务的一种思维方式,侧重于通过缩短交付周期和事件管理生命周期,并通过减少工作量来支持开发人员和运维人员来运维服务的原则。SRE团队的日常任务包括:
- 可用性
- 延迟
- 性能
- 效率
- 变更管理
- 监控和告警
- 应急响应
- 事件响应
- 准备工作
- 容量规划
SRE 的战略目标是:
- 使部署更加容易
- 提高或维持正常运行时间
- 针对应用性能去建设可视化能力
- 设置SLI 和SLO 以及错误预算
- 通过承担计算风险来提高速度
- 消除手动操作任务
- 降低故障成本以缩短新功能的周期时间
各个服务稳定性指标的定义介绍:
服务水平指标(SLI):跨各种应用程序定义一组标准的服务水平指标将帮助团队标准化整个堆栈的监控、日志记录和自动化
服务水平目标(SLO):服务运行”应该有多好”的目标值或范围
服务水平协议(SLA):是产品与其最终用户之间的协议,是与客户就服务可靠性签订的合同,简单表述为”SLA=SLO + consequences”. SRE 团队可能不参与定义SLA的过程,但是我们需要确保满足SLO .
减轻工作负担控制SRE团队的工作量
利用自身的开发技能尽可能消除手动流程的一个实例。让SRE 花费多达50%的时间来改进他们管理的系统是一种很高的做法。
错误预算
Availability = (Number of good events / Total events) * 100
Error budget = (100- Availability) = failed requests / (successful requests + failled requests)
变更是中断的最终原因,发布是变更的主要来源。最佳实践的思路
- 你是否在单个版本中引入了太多更改?请保持简单,并将你的版本分成更小的需求变更
- SLO 是否过于严格?你可能需要协商并放宽SLO
- 你的发布过程是否有任何导致问题的手动步骤?尝试引入自动化和测试
- 系统的架构是否容错?硬件故障、网络包丢失、上游或下游应用程序可能会出现异常行为。你的系统架构应该容忍这些故障。
- 开发团队是否解决了技术债问题?在急于发布新功能时,技术债常常被忽视。
- 你的监控和告警是否抓住了主要指标?不断增长的队列规模、网络速度变慢、潜在客户变更过多等等都可能导致下游事件。
- 你是否定期监控日志并保持其清洁?你的日志中可能存在不会立即导致问题的警告。但是,再加上其他基础设施问题,这些告警可能会导致重大事故。
监控分布式系统四大黄金指标
延迟:
流量:
错误:
饱和度:
利用率(四大以外的补充):
风险分析和度量
风险分析定义如下:可能导致违反SLO的项目列表:
- TDD 检测时间
- TTR 修复时间
- Freq/Yr 每年的错误频率
- Users 受影响的用户
- Bad/Yr 每年有异常的分钟数,相当于错误预算
Risk = TTD * TTR * (Freq /Yr) * (% of users)
if TTD = 0,
Risk = TTR * (Freq /Yr) * (% of users)
监控和告警
促进事后分析
“事后分析是无可指责的”, 故障解决后应尽快进行事后分析以及复盘。
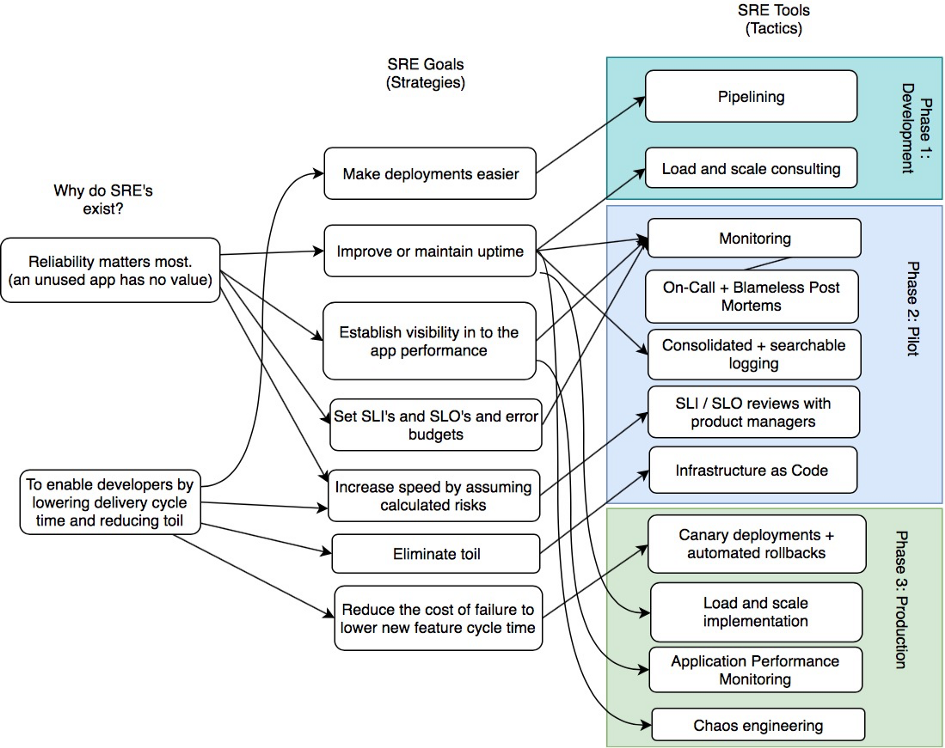
如何获取一个可靠的服务?
阶段1: Development
- 流水线
- 负载和容量考量
阶段2:Pilot
- 监控
- 轮值和无指责的事后分析
- 聚合和可检索的日志系统
- 和产品负责人定期审查SLI/SLO
- 基础设施即代码
阶段3:Production
- 灰度部署和自动回滚
- 负载和扩展执行
- 应用性能监控(APM)
- 混沌引擎










